Predicting the Orbital Obliquities of Exoplanets Using Machine Learning
As discussed in part 2 of this blog series, the current random forest model struggles to predict the orbital obliquities of exoplanets accurately. This may be due to factors such as the small sample size, imbalanced dataset, reliance on median imputation for missing data, insufficiently relevant features, and/or the random forest method being unsuitable for this problem. In part 3, I address these challenges with two enhancements: physically derived imputation and feature engineering.
-
Physically Derived Imputation: Instead of median-based imputation (replacement), missing values are calculated using established relationships between features. For example, the mass of a star can be derived from its effective temperature and radius, assuming it is on the main sequence. This approach produces more accurate and physically meaningful values compared to median replacement.
-
Feature Engineering: Orbital obliquity may depend more on combinations of features than individual ones. To test this, I created two new features: the planet-to-star mass ratio (Mp/M*) and planetary density. These features aim to better capture the dependencies related to obliquity.
Step 1: Physically Derive Missing Values
To improve the imputation strategy, I calculated missing values for certain features using known relationships. The full list of derived features and methodology is detailed in the Jupyter notebook. To do this, I created a loop that iterates through all of the rows to derive missing values wherever possible, based on other available features. If derivation is not feasible, the median value is used instead. For example, the planet mass can be inferred from its radius using the mass-radius relation provided by Muller et al. 2024.
Step 2: Feature engineering
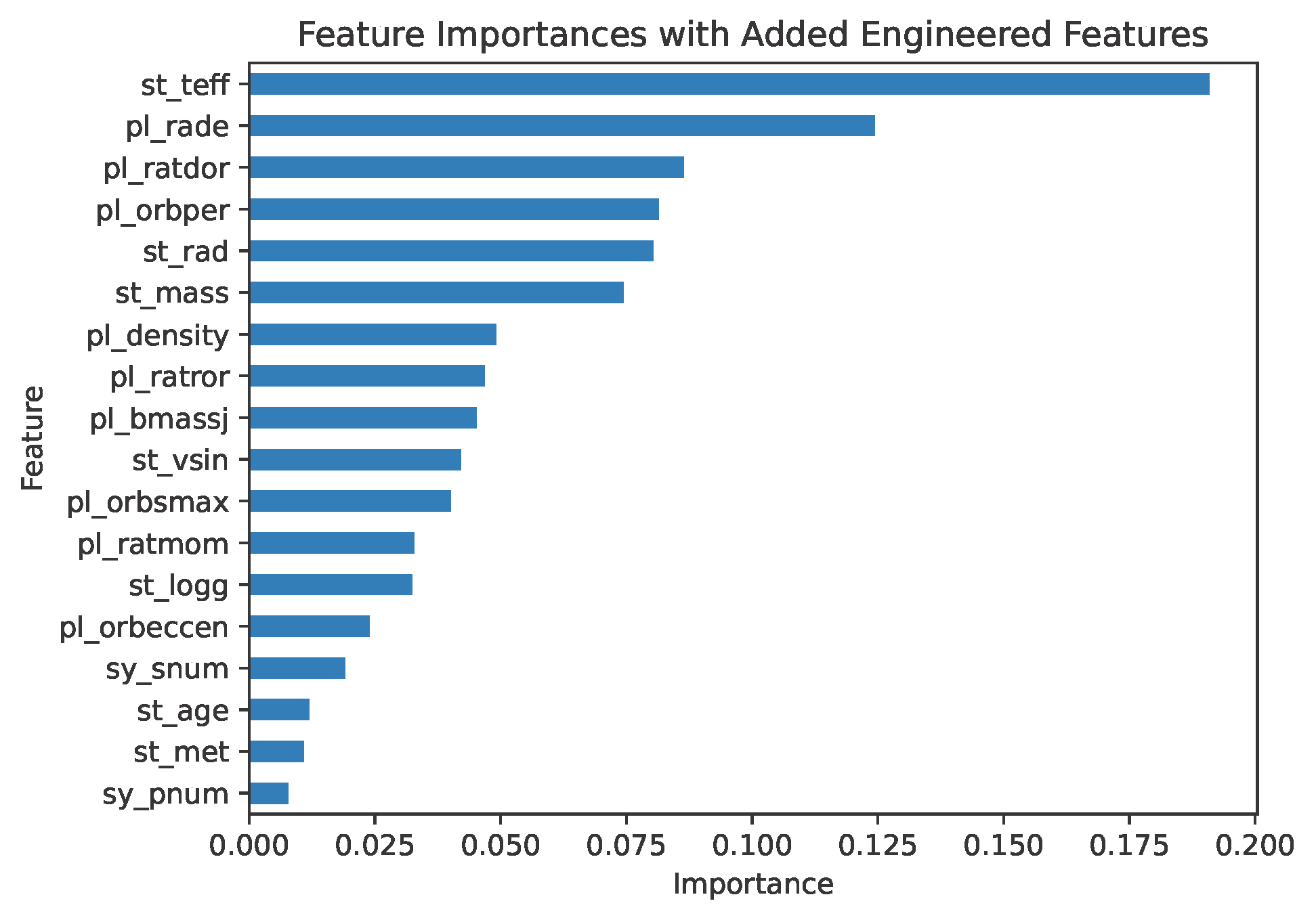
Two new features were added to try to improve the performance of the model: the planet-to-star mass ratio (pl_ratmom) and planetary density (pl_density). These features were selected because of their potential impact on obliquity, based on the feature importance plot shown in part 2, where the planet mass and radius (used to calculate planet density) and stellar mass (used to calculate the planet-to-star mass ratio) were ranked as some of the most important features in the model. Uncertainties for these features were calculated using standard error propagation techniques (see Vern Lindberg's guide).
Step 3: Retraining Random Forest Model and Comparing Results
Finally, I retrained the random forest model using both a simple train/test split and k-fold cross-validation (detailed in part 2). Unfortunately, the improvements were minimal and statistically insignificant. The mean and median R2 scores slightly changed from -0.11 and 0.22 (variance 0.52) to -0.01 and 0.19 (variance 0.38). These results suggest that while the new imputation method and engineered features add physical context, they did not significantly enhance the model's predictive ability. Below is a plot of predicted vs. measured obliquities, with a reference diagonal line indicating predicted = measured (error bar version here):

In reviewing the feature importance plot, the new features (pl_density and pl_ratmom) ranked 7th and 10th in importance, respectively. This indicates that while they add some value, their contribution to the model's predictive power is limited.
Summary and Next Steps
To summarize, the random forest regression models did not achieve high accuracy in predicting orbital obliquities of exoplanets. However, could a random forest classifier perform better at distinguishing between low and high obliquity orbits? In the next blog post, I will explore this question by using a classification approach to predict whether a planet's orbit is aligned (low obliquity) or misaligned (high obliquity) with its host star's equator.
Summary of the skills applied in this work: Python programming, Data Visualization, Data Imputation Strategies, Feature Engineering, Machine Learning, Random Forest Regression, K-Fold Cross-Validation.
< Previous Post | Data Science Home Page ⌂ | Next Post >